L'environnement de production chez Google, du point de vue d'un SRE
Les centres de données de Google sont très différents de la plupart des centres de données conventionnels et des fermes de serveurs à petite échelle. Ces différences présentent à la fois des problèmes et des opportunités supplémentaires. Ce chapitre aborde les défis et les opportunités qui caractérisent les centres de données Google et présente la terminologie utilisée tout au long de l’ouvrage.
Matériel
La plupart des ressources informatiques de Google se trouvent dans des centres de données conçus par Google et dotés de matériel propriétaire de distribution d’énergie, de refroidissement, de mise en réseau et de calcul (voir [Bar13]). Contrairement aux centres de données de colocation " standard “, le matériel de calcul d’un centre de données conçu par Google est le même pour tous.9 Pour éviter toute confusion entre le matériel et le logiciel de serveur, nous utilisons la terminologie suivante tout au long de cet ouvrage :
Machine
Une pièce de matériel (ou peut-être une VM)
Serveur
Une pièce de logiciel qui implémente un service.
Les machines peuvent exécuter n’importe quel serveur, nous ne consacrons donc pas de machines spécifiques à des programmes de serveur spécifiques. Il n’y a pas de machine spécifique qui exécute notre serveur de messagerie, par exemple. Au lieu de cela, l’allocation des ressources est gérée par notre système d’exploitation de cluster, Borg.
Nous sommes conscients que cette utilisation du mot serveur est inhabituelle. L’usage courant du mot fait l’amalgame entre “binaire qui accepte une connexion réseau” et machine, mais il est important de faire la différence entre les deux lorsqu’on parle d’informatique chez Google. Une fois que vous vous serez habitué à notre utilisation du mot serveur, vous comprendrez mieux pourquoi il est important d’utiliser cette terminologie spécialisée, non seulement au sein de Google mais aussi dans le reste de cet ouvrage.
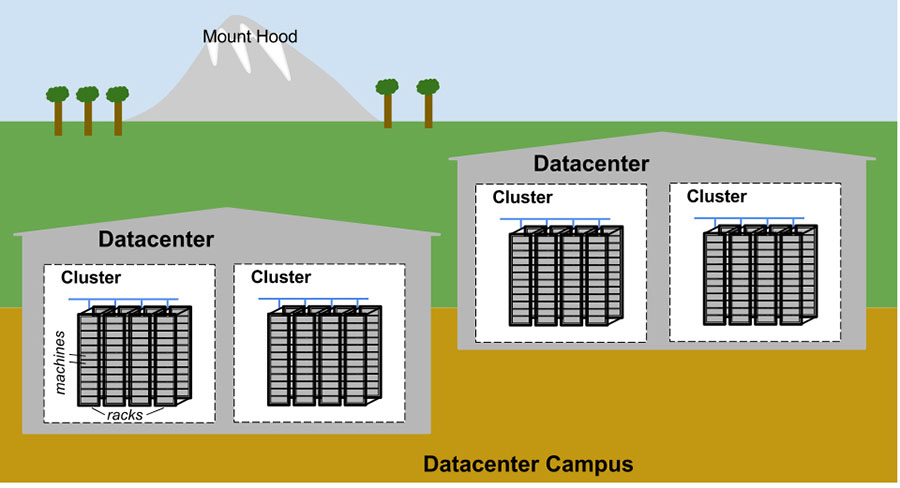
La figure 2-1 illustre la topologie d’un centre de données Google :
- Des dizaines de machines sont placées dans un rack.
- Les racks sont disposés en ligne.
- Une ou plusieurs rangées forment un cluster.
- En général, un bâtiment de datacenter abrite plusieurs clusters.
- Plusieurs bâtiments de centre de données situés à proximité les uns des autres forment un campus.
Les machines d’un centre de données donné doivent pouvoir communiquer entre elles. Nous avons donc créé un commutateur virtuel très rapide avec des dizaines de milliers de ports. Pour ce faire, nous avons connecté des centaines de commutateurs construits par Google dans une matrice réseau Clos [Clos53] appelée Jupiter [Sin15]. Dans sa plus grande configuration, Jupiter prend en charge une bande passante de 1,3 Pbps en bissection entre les serveurs.
Les centres de données sont reliés entre eux par notre réseau fédérateur B4 [Jai13], qui s’étend sur toute la planète. B4 est une architecture réseau définie par logiciel (et utilise le protocole de communication standard ouvert OpenFlow). Il fournit une bande passante massive à un nombre modeste de sites et utilise une allocation élastique de la bande passante pour maximiser la bande passante moyenne [Kum15].
Un logiciel système qui “organise” le matériel
Notre matériel doit être contrôlé et administré par un logiciel capable de gérer une échelle massive. Les pannes matérielles sont un problème notable que nous gérons par des logiciels. Étant donné le grand nombre de composants matériels dans un cluster, les pannes matérielles sont assez fréquentes. Dans un seul cluster, au cours d’une année type, des milliers de machines tombent en panne et des milliers de disques durs se brisent ; lorsqu’ils sont multipliés par le nombre de clusters que nous exploitons à l’échelle mondiale, ces chiffres deviennent quelque peu vertigineux. C’est pourquoi nous voulons soustraire ces problèmes aux utilisateurs, et les équipes qui gèrent nos services ne veulent pas non plus être dérangées par des pannes matérielles. Chaque campus de datacenter dispose d’équipes dédiées à la maintenance du matériel et de l’infrastructure du datacenter.
Gestion des machines
Borg, illustré à la Figure 2-2, est un système d’exploitation de cluster distribué [Ver15], similaire à Apache Mesos.10 Borg gère ses tâches au niveau du cluster.
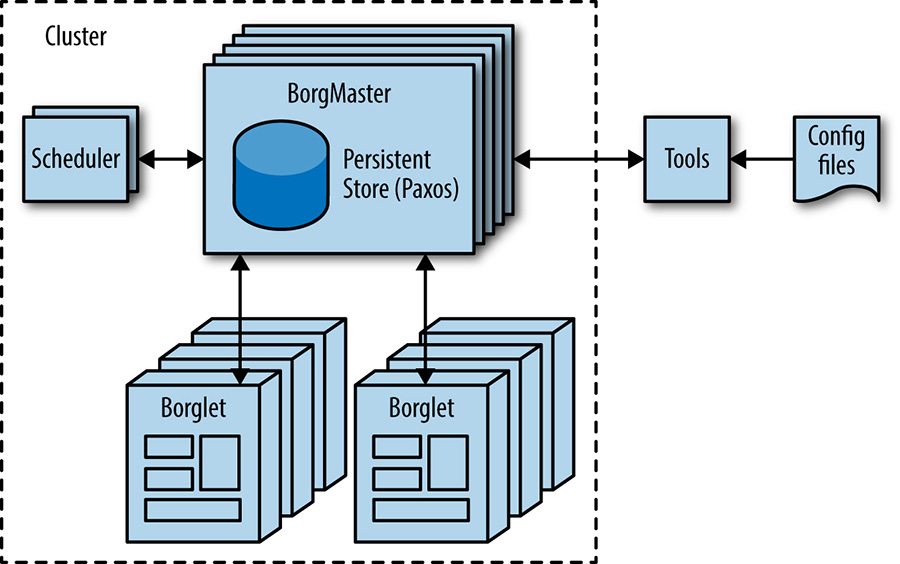
Borg est responsable de l’exécution des tâches des utilisateurs, qui peuvent être soit des serveurs fonctionnant indéfiniment, soit des processus batch comme MapReduce [Dea04]. Les tâches peuvent être constituées de plusieurs (et parfois de milliers) de tâches identiques, à la fois pour des raisons de fiabilité et parce qu’un seul processus ne peut généralement pas gérer tout le trafic du cluster. Lorsque Borg démarre un travail, il trouve des machines pour les tâches et leur demande de lancer le programme serveur. Borg surveille ensuite continuellement ces tâches. Si une tâche fonctionne mal, elle est tuée et redémarrée, éventuellement sur une autre machine.
Étant donné que les tâches sont allouées de manière fluide sur les machines, nous ne pouvons pas simplement nous fier aux adresses IP et aux numéros de port pour nous référer aux tâches. Nous résolvons ce problème par un niveau supplémentaire d’indirection : au démarrage d’une tâche, Borg attribue un nom et un numéro d’index à chaque tâche à l’aide du Borg Naming Service (BNS). Plutôt que d’utiliser l’adresse IP et le numéro de port, les autres processus se connectent aux tâches Borg via le nom BNS, qui est traduit en adresse IP et numéro de port par le BNS. Par exemple, le chemin BNS peut être une chaîne de caractères telle que /bns////, qui se résout en :.
Borg est également responsable de l’allocation des ressources aux tâches. Chaque tâche doit spécifier les ressources dont elle a besoin (par exemple, 3 cœurs de CPU, 2 Go de RAM). À l’aide de la liste des exigences de tous les travaux, Borg peut répartir les tâches sur les machines d’une manière optimale qui tient également compte des domaines de défaillance (par exemple : Borg n’exécutera pas toutes les tâches d’une tâche sur le même rack, car cela signifie que le commutateur du haut du rack constitue un point de défaillance unique pour cette tâche).
Si une tâche tente d’utiliser plus de ressources qu’elle n’en a demandé, Borg tue la tâche et la redémarre (car une tâche qui s’effondre lentement est généralement préférable à une tâche qui n’a pas été redémarrée du tout).
Stockage
Les tâches peuvent utiliser le disque local des machines comme espace de grattage, mais nous disposons de plusieurs options de stockage en cluster pour le stockage permanent (et même l’espace de grattage finira par passer au modèle de stockage en cluster). Ces options sont comparables à Lustre et au système de fichiers distribués Hadoop (HDFS), qui sont tous deux des systèmes de fichiers en cluster open source.
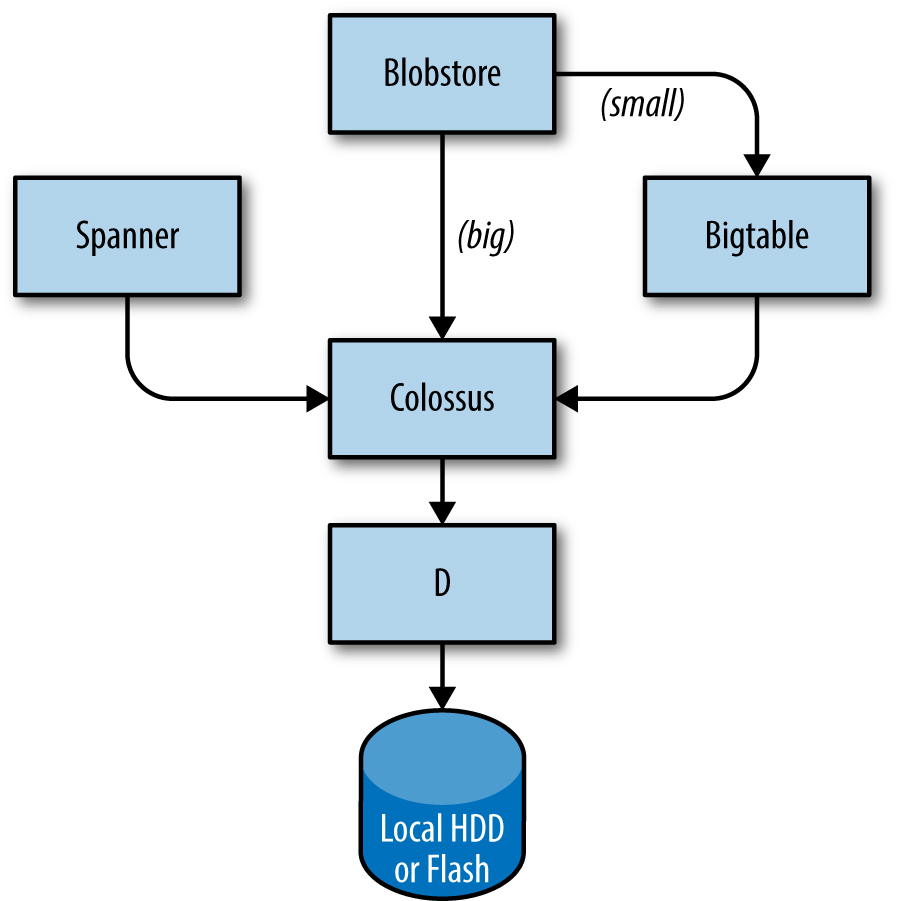
La couche de stockage est chargée d’offrir aux utilisateurs un accès facile et fiable au stockage disponible pour un cluster. Comme le montre la figure 2-3, le stockage comporte plusieurs couches :
La couche la plus basse est appelée D (pour disk, bien que D utilise à la fois des disques rotatifs et du stockage flash). D est un serveur de fichiers fonctionnant sur presque toutes les machines d’un cluster. Cependant, les utilisateurs qui veulent accéder à leurs données ne veulent pas avoir à se rappeler quelle machine stocke leurs données, et c’est là que la couche suivante entre en jeu. La couche supérieure de D, appelée Colossus, crée un système de fichiers à l’échelle du cluster qui offre la sémantique habituelle des systèmes de fichiers, ainsi que la réplication et le cryptage. Colossus est le successeur de GFS, le système de fichiers de Google [Ghe03]. Il existe plusieurs services de type base de données construits sur Colossus :
Bigtable [Cha06] est un système de base de données NoSQL capable de gérer des bases de données d’une taille de plusieurs pétaoctets. Une Bigtable est une carte triée multidimensionnelle éparse, distribuée et persistante, indexée par une clé de ligne, une clé de colonne et un horodatage ; chaque valeur de la carte est un tableau d’octets non interprété. Bigtable supporte éventuellement la réplication cohérente entre les centres de données. Spanner [Cor12] offre une interface de type SQL pour les utilisateurs qui ont besoin d’une cohérence réelle à travers le monde. Plusieurs autres systèmes de bases de données, tels que Blobstore, sont disponibles. Chacune de ces options s’accompagne de son propre ensemble de compromis (voir Intégrité des données : ce que vous lisez est ce que vous avez écrit).
Mise en réseau
Le matériel réseau de Google est contrôlé de plusieurs façons. Comme indiqué précédemment, nous utilisons un réseau défini par logiciel basé sur OpenFlow. Au lieu d’utiliser du matériel de routage “intelligent”, nous nous appuyons sur des composants de commutation “muets” moins coûteux, associés à un contrôleur central (dupliqué) qui précalcule les meilleurs chemins sur le réseau. Par conséquent, nous sommes en mesure d’éloigner des routeurs les décisions de routage coûteuses en calcul et d’utiliser du matériel de commutation simple.
La bande passante du réseau doit être allouée judicieusement. Tout comme Borg limite les ressources de calcul qu’une tâche peut utiliser, l’exécuteur de la bande passante (BwE) gère la bande passante disponible afin de maximiser la bande passante moyenne disponible. L’optimisation de la bande passante n’est pas seulement une question de coût : il a été démontré que l’ingénierie centralisée du trafic permet de résoudre un certain nombre de problèmes qui sont traditionnellement extrêmement difficiles à résoudre en combinant le routage distribué et l’ingénierie du trafic [Kum15].
Dans certains services, les tâches sont exécutées dans plusieurs clusters, répartis dans le monde entier. Afin de minimiser la latence des services distribués à l’échelle mondiale, nous voulons diriger les utilisateurs vers le centre de données le plus proche ayant une capacité disponible. Notre équilibreur de charge logiciel global (GSLB) effectue un équilibrage de charge à trois niveaux :
- Équilibrage de la charge géographique pour les requêtes DNS (par exemple, vers www.google.com), décrit dans Équilibrage de la charge au niveau du front-end.
- Équilibrage de la charge au niveau d’un service utilisateur (par exemple, YouTube ou Google Maps)
- Équilibrage de la charge au niveau des appels de procédure à distance (RPC), décrit dans Équilibrage de la charge dans le centre de données.
Les propriétaires de services spécifient un nom symbolique pour un service, une liste d’adresses BNS de serveurs et la capacité disponible à chacun des emplacements (généralement mesurée en requêtes par seconde). GSLB dirige alors le trafic vers les adresses BNS.
Autres logiciels du système
Plusieurs autres composants d’un centre de données sont également importants.
Service de verrouillage
Le service de verrouillage Chubby [Bur06] fournit une API de type système de fichiers pour le maintien des verrous. Chubby gère ces verrous dans tous les centres de données. Il utilise le protocole Paxos pour le consensus asynchrone (voir Gestion de l’état critique : consensus distribué pour la fiabilité).
Chubby joue également un rôle important dans l’élection du maître. Lorsqu’un service a cinq répliques d’un travail en cours d’exécution pour des raisons de fiabilité, mais qu’une seule réplique peut effectuer le travail réel, Chubby est utilisé pour sélectionner la réplique qui peut continuer.
Les données qui doivent être cohérentes se prêtent bien au stockage dans Chubby. C’est pourquoi le BNS utilise Chubby pour stocker le mappage entre les chemins du BNS et les paires adresse IP:port.
Surveillance et alerte
Nous voulons nous assurer que tous les services fonctionnent comme il se doit. C’est pourquoi nous exécutons de nombreuses instances de notre programme de surveillance Borgmon (voir “Alertes pratiques à partir de données chronologiques”). Borgmon " récupère " régulièrement les métriques des serveurs surveillés. Ces mesures peuvent être utilisées instantanément pour des alertes, mais aussi stockées pour être utilisées dans des vues d’ensemble historiques (par exemple, des graphiques). Nous pouvons utiliser la surveillance de plusieurs façons :
- Mettre en place des alertes pour les problèmes aigus.
- Comparer les comportements : une mise à jour logicielle a-t-elle rendu le serveur plus rapide ?
- Examiner comment le comportement de consommation des ressources évolue dans le temps, ce qui est essentiel pour la planification de la capacité.
Notre infrastructure logicielle
Notre architecture logicielle est conçue pour utiliser le plus efficacement possible notre infrastructure matérielle. Notre code est fortement multithreadé, de sorte qu’une tâche peut facilement utiliser plusieurs cœurs. Pour faciliter les tableaux de bord, le suivi et le débogage, chaque serveur dispose d’un serveur HTTP qui fournit des diagnostics et des statistiques pour une tâche donnée.
Tous les services de Google communiquent à l’aide d’une infrastructure d’appel de procédure à distance (RPC) appelée Stubby ; une version open source, gRPC, est disponible.11 Souvent, un appel RPC est effectué même lorsqu’un appel à une sous-routine du programme local doit être réalisé. Cela facilite le remaniement de l’appel dans un serveur différent si une plus grande modularité est nécessaire, ou lorsque la base de code d’un serveur se développe. GSLB peut équilibrer la charge des RPC de la même manière qu’il équilibre la charge des services visibles de l’extérieur.
Un serveur reçoit des demandes RPC de son frontend et envoie des RPC à son backend. En termes traditionnels, le front-end est appelé le client et le back-end est appelé le serveur.
Les données sont transférées vers et depuis un RPC à l’aide de tampons de protocole12, souvent abrégés en “protobufs”, qui sont similaires à Thrift d’Apache. Les tampons de protocole présentent de nombreux avantages par rapport à XML pour la sérialisation des données structurées : ils sont plus simples à utiliser, 3 à 10 fois plus petits, 20 à 100 fois plus rapides et moins ambigus.
Notre environnement de développement
La rapidité du développement est très importante pour Google, c’est pourquoi nous avons construit un environnement de développement complet pour utiliser notre infrastructure [Mor12b].
À l’exception de quelques groupes qui disposent de leurs propres dépôts de sources ouvertes (par exemple, Android et Chrome), les ingénieurs logiciels de Google travaillent à partir d’un seul dépôt partagé [Pot16]. Cela a quelques implications pratiques importantes pour nos flux de travail :
- Si les ingénieurs rencontrent un problème dans un composant extérieur à leur projet, ils peuvent corriger le problème, envoyer les modifications proposées (” changelist “, ou CL) au propriétaire pour révision, et soumettre le CL à la ligne principale.
- Les modifications apportées au code source dans le propre projet d’un ingénieur nécessitent une révision. Tous les logiciels sont révisés avant d’être soumis.
Lorsque le logiciel est construit, la demande de construction est envoyée aux serveurs de construction dans un centre de données. Même les builds volumineux sont exécutés rapidement, car de nombreux serveurs de build peuvent compiler en parallèle. Cette infrastructure est également utilisée pour les tests continus. Chaque fois qu’une CL est soumise, des tests sont exécutés sur tous les logiciels qui peuvent dépendre de cette CL, directement ou indirectement. Si le framework détermine que la modification est susceptible de casser d’autres parties du système, il en informe le propriétaire de la modification soumise. Certains projets utilisent un système “push-on-green”, où une nouvelle version est automatiquement mise en production après avoir passé les tests.
Shakespeare : Un exemple de service
Pour illustrer la manière dont un service pourrait être déployé dans l’environnement de production de Google, examinons un exemple de service qui interagit avec plusieurs technologies Google. Supposons que nous voulions proposer un service qui vous permette de déterminer où un mot donné est utilisé dans toutes les œuvres de Shakespeare.
Nous pouvons diviser ce système en deux parties :
- Un composant batch qui lit tous les textes de Shakespeare, crée un index, et écrit l’index dans une Bigtable. Ce travail ne doit être exécuté qu’une seule fois, ou peut-être très rarement (car on ne sait jamais si un nouveau texte peut être découvert !).
- Une application frontale qui traite les demandes des utilisateurs finaux. Ce travail est toujours en cours, car les utilisateurs de tous les fuseaux horaires voudront faire des recherches dans les livres de Shakespeare.
Le composant batch est un MapReduce comprenant trois phases.
La phase de cartographie lit les textes de Shakespeare et les divise en mots individuels. Cette opération est plus rapide si elle est effectuée en parallèle par plusieurs travailleurs.
La phase de brassage trie les tuples par mot.
Dans la phase de réduction, un tuple de (mot, liste d’emplacements) est créé.
Chaque tuple est écrit dans une ligne d’une Bigtable, en utilisant le mot comme clé.
Vie d’une requête
La figure 2-4 montre comment la requête d’un utilisateur est traitée : tout d’abord, l’utilisateur dirige son navigateur vers shakespeare.google.com. Pour obtenir l’adresse IP correspondante, l’appareil de l’utilisateur résout l’adresse avec son serveur DNS (1). Cette requête aboutit finalement au serveur DNS de Google, qui communique avec GSLB. Comme le GSLB suit la charge de trafic entre les serveurs frontaux dans les différentes régions, il choisit l’adresse IP du serveur à envoyer à cet utilisateur.
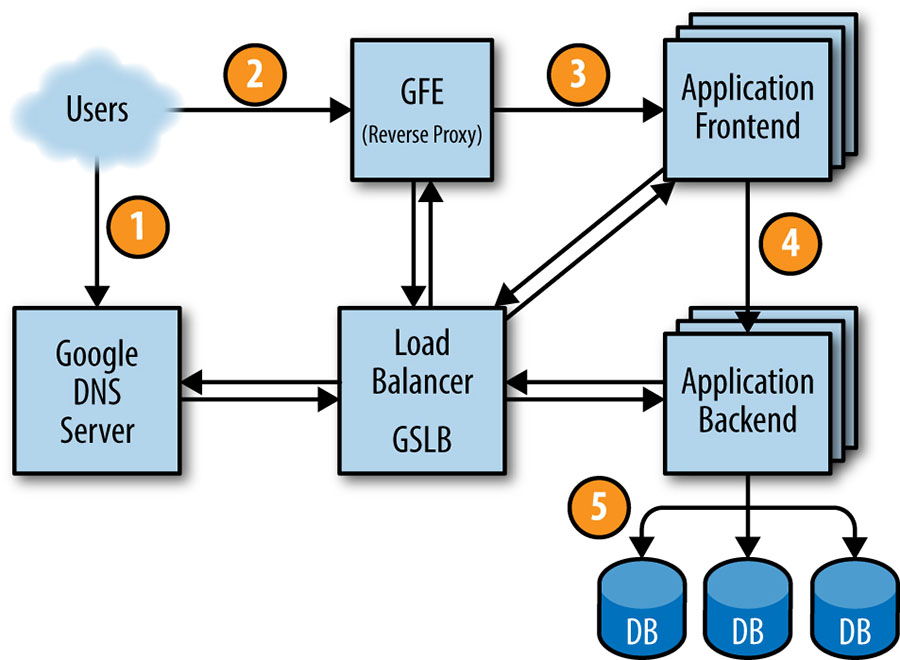
Le navigateur se connecte au serveur HTTP sur cette IP. Ce serveur (appelé Google Frontend, ou GFE) est un reverse proxy qui termine la connexion TCP (2). Le GFE recherche le service requis (recherche sur le Web, cartes ou, dans ce cas, Shakespeare). Toujours en utilisant GSLB, le serveur trouve un serveur frontal Shakespeare disponible et envoie à ce serveur un RPC contenant la demande HTTP (3).
Le serveur Shakespeare analyse la requête HTTP et construit un protobuf contenant le mot à rechercher. Le serveur frontal Shakespeare doit maintenant contacter le serveur dorsal Shakespeare : le serveur frontal contacte GSLB pour obtenir l’adresse BNS d’un serveur dorsal approprié et non chargé (4). Ce serveur backend Shakespeare contacte alors un serveur Bigtable pour obtenir les données demandées (5).
La réponse est écrite dans le protobuf de réponse et renvoyée au serveur dorsal Shakespeare. Le backend transmet un protobuf contenant les résultats au serveur frontal Shakespeare, qui assemble le HTML et renvoie la réponse à l’utilisateur.
Toute cette chaîne d’événements est exécutée en un clin d’œil - quelques centaines de millisecondes seulement ! Comme de nombreuses pièces mobiles sont impliquées, il existe de nombreux points de défaillance potentiels ; en particulier, une défaillance du GSLB ferait des ravages. Cependant, les politiques de Google en matière de tests rigoureux et de déploiement minutieux, ainsi que nos méthodes proactives de récupération des erreurs telles que la dégradation progressive, nous permettent de fournir le service fiable que nos utilisateurs attendent. Après tout, les gens utilisent régulièrement www.google.com pour vérifier si leur connexion Internet est correctement configurée.
Organisation des tâches et des données
Les tests de charge ont déterminé que notre serveur dorsal peut gérer environ 100 requêtes par seconde (QPS). Les essais effectués avec un ensemble limité d’utilisateurs nous amènent à prévoir une charge de pointe d’environ 3 470 QPS, ce qui signifie que nous avons besoin d’au moins 35 tâches. Cependant, les considérations suivantes signifient que nous avons besoin d’au moins 37 tâches dans le travail, ou N+2 :
- Pendant les mises à jour, une tâche à la fois sera indisponible, ce qui laisse 36 tâches.
- Une panne de machine peut se produire pendant une mise à jour de tâche, laissant seulement 35 tâches, juste assez pour servir la charge de pointe.13
Un examen plus approfondi du trafic utilisateur montre que notre pic d’utilisation est réparti à l’échelle mondiale : 1 430 QPS en Amérique du Nord, 290 en Amérique du Sud, 1 400 en Europe et en Afrique, et 350 en Asie et en Australie. Au lieu de placer tous les backends sur un seul site, nous les répartissons entre les États-Unis, l’Amérique du Sud, l’Europe et l’Asie. En tenant compte de la redondance N+2 par région, nous nous retrouvons avec 17 tâches aux États-Unis, 16 en Europe et 6 en Asie. Cependant, nous décidons d’utiliser 4 tâches (au lieu de 5) en Amérique du Sud, afin de réduire l’overhead de N+2 à N+1. Dans ce cas, nous sommes prêts à tolérer un petit risque de latence plus élevée en échange de coûts matériels moindres : si GSLB redirige le trafic d’un continent à l’autre lorsque notre centre de données sud-américain est surchargé, nous pouvons économiser 20% des ressources que nous dépenserions en matériel. Dans les grandes régions, nous répartirons les tâches sur deux ou trois clusters pour une meilleure résilience.
Étant donné que les backends doivent contacter la Bigtable contenant les données, nous devons également concevoir cet élément de stockage de manière stratégique. Un backend en Asie contactant une Bigtable aux États-Unis ajoute une latence significative, nous répliquons donc la Bigtable dans chaque région. La réplication de la Bigtable nous aide de deux façons : elle fournit une résilience en cas de défaillance d’un serveur Bigtable, et elle réduit la latence d’accès aux données. Bien que Bigtable n’offre qu’une cohérence éventuelle, ce n’est pas un problème majeur car nous n’avons pas besoin de mettre à jour le contenu souvent.
Nous avons introduit beaucoup de terminologie ici ; bien que vous n’ayez pas besoin de vous en souvenir, elle est utile pour encadrer de nombreux autres systèmes auxquels nous nous référerons plus tard.