Split brain
Comment identifier un cerveau divisé dans Elasticsearch ?
Résumé
Cet article explique comment identifier une situation de “split brain” dans Elasticsearch.
Environnement
- Clusters ECE/ECK.
- Clusters Elasticsearch sur site.
Etapes
- Rassembler les résultats de l’appel d’api GET _cat/nodes.
- Vérifier les journaux d’Elasticsearch et rechercher les éléments suivants :
org.elasticsearch.cluster.coordination.CoordinationStateRejectedException: This node previously joined a cluster with UUID [<cluster UUID>] and is now trying to join a different cluster with UUID [<cluster UUID>]. This is forbidden and usually indicates an incorrect discovery or cluster bootstrapping configuration. Note that the cluster UUID persists across restarts and can only be changed by deleting the contents of the node's data path [/app/data] which will also remove any data held by this node.
Caused by: org.elasticsearch.cluster.coordination.CoordinationStateRejectedException: This node previously joined a cluster with UUID [<cluster UUID>] and is now trying to join a different cluster with UUID [<cluster UUID>. This is forbidden and usually indicates an incorrect discovery or cluster bootstrapping configuration. Note that the cluster UUID persists across restarts and can only be changed by deleting the contents of
"o.e.c.c.ClusterFormationFailureHelper", "cluster.name": "prod-elasticsearch", "node.name": "prod-elasticsearch-es-master-node-01-1", "message": "master not discovered or elected yet, an election requires at least 3 nodes with ids from [LQkkydP3Rpy-D0s-7bN2WA, WYA9Il8VT0-1G9cMWSopvA, QI9viq8iQ06VirnZyhq1DQ, 80tJ5e5rRHy6U0iJ-wcIrg, 6HLXSPOYTKCve9Zg91rlPw], have discovered
En cas d’apparition d’un cerveau divisé, les articles suivants peuvent vous être utiles pour résoudre les problèmes : - Résolution des scénarios de cerveau divisé dans les déploiements de la ECE.
Résoudre les scénarios de cerveau divisé dans les déploiements de l’ECE
Il n’est pas courant que les déploiements ECE se retrouvent dans une situation de “split-brain” où plus d’un nœud éligible au statut de maître est élu comme maître et le déploiement est divisé en deux clusters Elasticsearch. Cependant, cela peut arriver dans certaines situations, et cet article décrit les étapes qui peuvent être utilisées pour résoudre le scénario “split-brain” et ramener le déploiement dans la topologie correcte d’un seul cluster.
Remarque : il est fortement recommandé de disposer d’une sauvegarde instantanée des données de votre déploiement avant d’effectuer ces étapes. Les étapes fournies peuvent être exécutées en toute sécurité, mais il est vivement recommandé de disposer d’une sauvegarde instantanée à restaurer chaque fois que des modifications sont apportées à la topologie d’un déploiement, au cas où quelque chose d’inattendu se produirait.
Notre exemple de topologie
Nous allons utiliser un exemple de déploiement ECE à trois zones qui devrait avoir une topologie de :
- 3 nœuds éligibles au titre de maître nommés instance-00000001 (élu maître), instance-00000002, et instance-00000003
- 3 nœuds de coordination nommés instance-00000004, instance-00000005 et instance-00000006
- 3 nœuds de données nommés instance-00000007, instance-00000008 et instance-00000009
Dans ce scénario, nous nous sommes également retrouvés avec des nœuds supplémentaires qui ne devraient pas figurer dans la topologie et qui sont répartis dans deux des trois zones :
- 2 nœuds éligibles au statut de maître nommés instance-00000010 (également élu comme maître), et instance-00000011
L’objectif ici est de se débarrasser de ces deux nœuds supplémentaires éligibles au statut de maître qui se sont retrouvés dans le déploiement et de revenir à la topologie originale mentionnée ci-dessus où il y a un seul nœud maître élu et deux nœuds éligibles au statut de maître.
Ce qu’il faut essayer en premier
Souvent, l’exécution d’un changement de plan “no-op” sans apporter de modifications au déploiement permet à ce dernier de se reconfigurer dans la topologie correcte. Cependant, si votre changement de plan “no-op” échoue avec une erreur indiquant que le déploiement est en “split-brain”, vous devez d’abord essayer les étapes énumérées ci-dessous avant de passer aux étapes plus avancées :
- Mettez en pause les nœuds maîtres inutiles. Dans notre exemple de topologie, il s’agirait de 2 des 5 nœuds éligibles au statut de maître qui font partie du déploiement, nous mettrons donc en pause l’instance-00000010 et l’instance-00000011, bien que la mise en pause de n’importe quelle instance éligible au statut de maître devrait convenir.
- Exécutez un changement de plan sans arrêt en naviguant vers Déploiements -> <Nom_du_déploiement> -> Modifier et cliquez ensuite sur le bouton Enregistrer sans apporter de modifications au déploiement.
- Vérifiez que le déploiement a supprimé les deux nœuds éligibles au statut de maître inutiles et qu’il n’y a plus qu’un seul maître élu dans le déploiement.
Si vous obtenez toujours le message d’erreur “split-brain” ou si le changement de plan se bloque en essayant d’élire un nœud maître, vous devrez passer aux étapes avancées.
Étapes avancées
Assurez-vous que tous les nœuds de données du déploiement sont en cours de routage. Vous pouvez le vérifier en naviguant vers Déploiements -> <Nom_du_déploiement> -> Elasticsearch et en vérifiant les tuiles de chacun de vos nœuds de données. Un nœud qui n’est pas en train de router affichera un message “Not routing requests” sur la tuile :
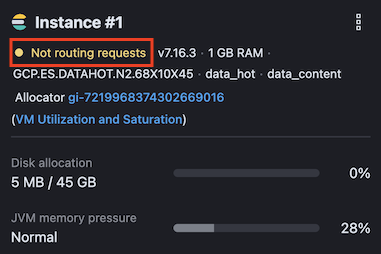
Pour rétablir le routage des nœuds de données, sélectionnez les trois ellipses de points dans le coin supérieur droit de la tuile et choisissez l’option Start routing requests (Commencer les demandes de routage).

Faites ceci pour tous les noeuds de données qui ne sont pas en train de router avant de passer à l’étape suivante. Dans notre exemple de topologie, nous voulons nous assurer que les instances-00000007, instance-00000008, et instance-00000009 sont toutes en cours de routage puisqu’il s’agit de nos noeuds de données.
Exécutez un GET _cluster/health et vérifiez que la santé du cluster est verte, indiquant que tous les shards pour tous les index ont été assignés aux noeuds de données :
{
"cluster_name": "446042047aa44b598fb72c027342592e",
"status": "green",
"timed_out": false,
"number_of_nodes": 9,
"number_of_data_nodes": 3,
"active_primary_shards": 12,
"active_shards": 24,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
Si l’état est jaune ou rouge, corrigez d’abord les problèmes d’affectation des shards avant de poursuivre. L’API cat shards et l’API Cluster allocation explain peuvent vous aider à identifier les shards non affectés et la raison pour laquelle ils ne le sont pas.
Mettez en pause tous les nœuds maîtres élus, à l’exception d’un seul. Pour ce faire, sélectionnez les trois ellipses de points dans le coin supérieur droit de la tuile du nœud maître, puis choisissez l’option Pause de l’instance.

Dans notre exemple de topologie, nous avons deux nœuds élus comme maîtres, nommés instance-00000001 et instance-00000010. Nous allons commencer par mettre en pause l’instance-00000001 et laisser l’instance-00000010 fonctionner en tant que maître élu.
- Exécutez un GET _cat/nodes?v et vérifiez la sortie. Vous devriez voir un noeud maître élu listé avec vos noeuds de données. Il peut y avoir d’autres noeuds listés aussi, mais vous voulez vous assurer que vous voyez vos noeuds maîtres et TOUS les noeuds de données au minimum dans la sortie. Si c’est le cas, vous avez identifié le nœud maître correct pour le déploiement. Si vous ne voyez pas tous les nœuds de données, alors vous avez identifié le mauvais nœud maître et vous devez répéter l’étape 3 ci-dessus et mettre en pause le nœud maître actuel tout en mettant en pause un autre nœud maître et en vérifiant à nouveau la sortie GET _cat/nodes?v.
Après avoir mis en pause l’instance-00000001 dans notre topologie d’exemple et exécuté un GET _cat/nodes?v , nous avons vu que les nœuds suivants étaient répertoriés :
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.10.10.1 65 95 0 0.33 0.58 0.62 ir - instance-0000000004
10.10.10.2 26 88 0 1.67 1.82 1.76 ir - instance-0000000005
10.10.10.3 29 100 0 2.11 1.73 1.67 ir - instance-0000000006
10.10.10.4 49 94 0 0.96 0.61 0.54 mr - instance-0000000011
10.10.10.5 49 94 0 0.96 0.61 0.54 mr * instance-0000000010
Nous voyons que les quatre nœuds listés avec notre nœud maître sont nos trois nœuds de coordination et l’un des nœuds éligibles au maître qui ont été ajoutés, mais pas nos trois nœuds de données. Ce n’est pas le bon maître.
Nous mettons en pause l’instance-0000000001 et l’instance-0000000010 et lançons à nouveau GET _cat/nodes?v et obtenons cette fois-ci cette sortie :
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.10.10.6 65 95 0 0.33 0.58 0.62 hrst - instance-0000000007
10.10.10.7 26 88 0 1.67 1.82 1.76 hrst - instance-0000000008
10.10.10.8 29 100 0 2.11 1.73 1.67 hrst - instance-0000000009
10.10.10.10 49 94 0 0.96 0.61 0.54 mr - instance-0000000002
10.10.10.11 49 94 0 0.96 0.61 0.54 mr - instance-0000000003
10.10.10.9 49 94 0 0.96 0.61 0.54 mr * instance-0000000001
Nous voyons maintenant nos trois nœuds de données ainsi que le nœud maître et deux de nos nœuds éligibles au statut de maître, il s’agit donc du bon maître. Il est possible que les deux clusters aient été divisés différemment que dans cet exemple. Nous aurions pu avoir des nœuds de coordination joints au bon maître par exemple, mais la chose importante à regarder dans cette sortie est si vous voyez vos nœuds de données listés.
Remarque : il est également possible que des nœuds de données soient répertoriés dans plusieurs sorties avec des nœuds maîtres différents. Dans ce cas, pour déterminer le bon nœud maître, après avoir changé de maître, assurez-vous que le nombre de shards est correct et attendez que les shards se propagent s’ils ne sont pas déjà récupérés.
Prenez note des instances rapportées par ce maître qui rapporte vos nœuds de données. Dans notre exemple de topologie, les nœuds de données rapportés par le maître sont instance-0000000007, instance-0000000008, et instance-0000000009. Nous montrons également les deux autres noeuds éligibles pour le maître qui sont instance-0000000002 et instance-0000000003.
Mettez en pause/démarrez le routage sur tous les noeuds qui ont été découverts dans l’étape précédente s’ils ne sont pas déjà en cours d’exécution.
Mettez en pause les instances restantes et dressez une liste des noms d’instance.
Dans notre exemple de topologie, après avoir exclu les nœuds découverts à l’étape 5, il nous reste la liste suivante de nœuds à supprimer du déploiement :
instance-0000000004
instance-0000000005
instance-0000000006
instance-0000000010
instance-0000000011
Naviguez vers Deployments -> <Nom_du_déploiement> -> Edit -> Advanced Edit -> Deployment Configuration pour ajouter les instances de l’étape 7 à la liste move_instances dans le bloc transient de la configuration de déploiement.
Le bloc de configuration transitoire pour notre exemple de topologie se présente comme suit :
"transient": {
"plan_configuration": {
"move_instances": [
{
"from": "instance-0000000004"
},
{
"from": "instance-0000000005"
},
{
"from": "instance-0000000006"
},
{
"from": "instance-0000000010"
},
{
"from": "instance-0000000011"
}
],
...
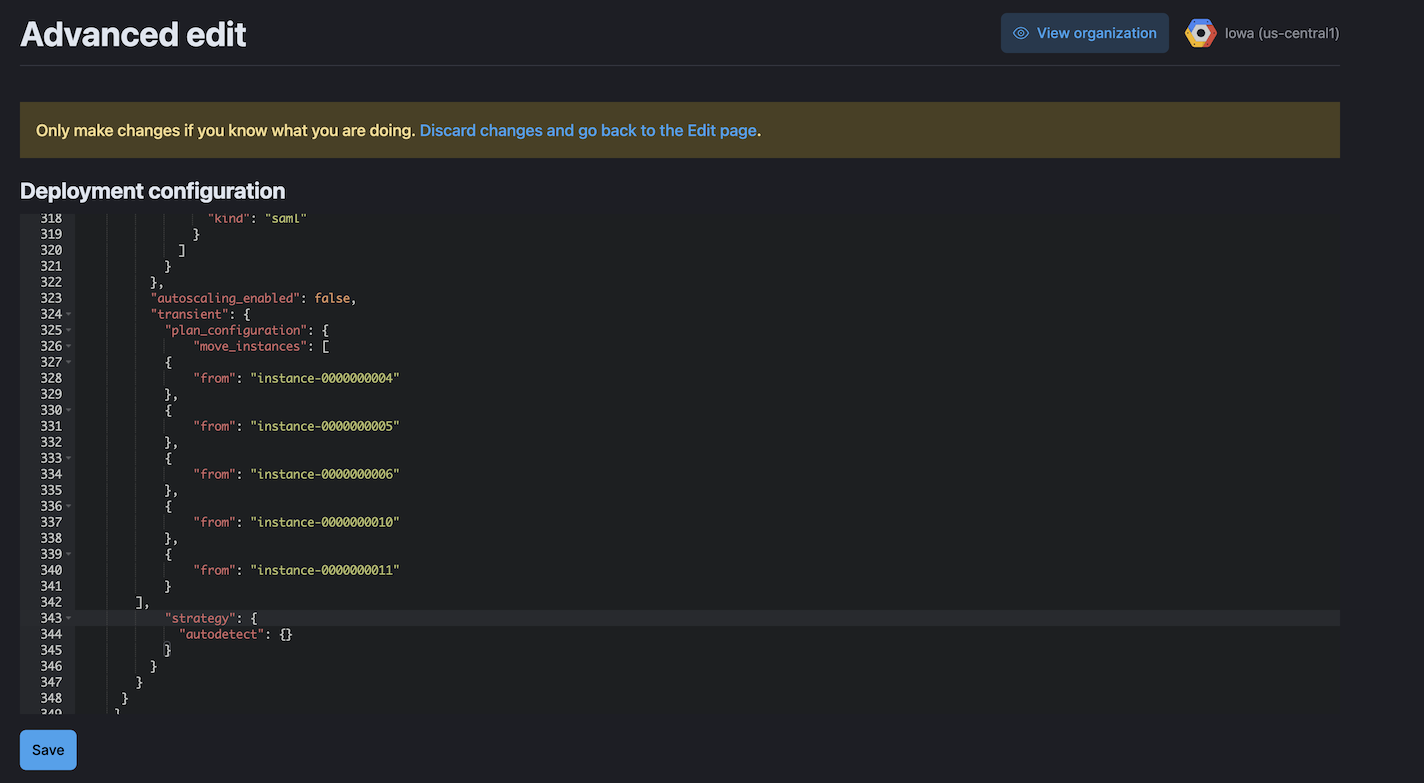
Cliquez sur Save pour sauvegarder le plan et effectuer le déplacement des instances. Cela permettra à ECE de reconfigurer le déploiement selon la topologie correcte et de se débarrasser des instances supplémentaires éligibles au statut de maître qui ne devraient pas faire partie du déploiement. Cela ramènera également le déploiement à un seul nœud maître élu.
Si, pour une raison quelconque, les étapes énumérées dans cet article ne permettent pas de résoudre le problème de “split-brain” dans votre déploiement, veuillez contacter le support Elastic pour obtenir de l’aide.