ECE Haute disponibilité
ECE est une solution d’orchestration de clusters Elasticsearch de manière centralisée. Cette solution permet de provisionner, gérer et monitorer Elasticsearch et Kibana depuis une seule console.
Une solution permettant de gérer des clusters issue de Cloud privé et/ou privé.
Sources
ECE Produit
ECE Training Fondamentaux
ECE Support
ECE Documentation
Elastic Cloud Entreprise Haute disponibilité
Tolérance aux pannes
Pour la ECE, la tolérance aux pannes est basée sur le concept de zones de disponibilité.
Une zone de disponibilité peut être un rack, une zone de serveur, une zone sur une plate-forme en nuage telle que AWS ou GCP, ou même une autre contrainte logique qui soutient l’exigence selon laquelle vous pourriez perdre toute la zone de disponibilité et pourtant votre cluster serait toujours opérationnel.
Une zone de disponibilité contient les ressources dont dispose une installation ECE qui sont isolées des autres zones de disponibilité pour se prémunir contre une éventuelle défaillance. Dans un cluster Elasticsearch tolérant aux défaillances, les nœuds d’un cluster doivent être répartis sur deux ou trois zones de disponibilité afin de garantir que le cluster puisse survivre à la défaillance d’une zone de disponibilité. Selon cette pratique, si une zone de disponibilité tombe complètement en panne, les autres zones de disponibilité non affectées peuvent supporter la charge de travail. En outre, les nœuds Elasticsearch sont lancés dans chacune des zones de disponibilité lorsque votre cluster est approvisionné. Lors du déploiement de grappes dans plusieurs zones de disponibilité, la sensibilisation à l’allocation des tessons garantit que les tessons primaires et leurs répliques sont répartis dans différentes zones afin de minimiser le risque de perdre toutes les copies de tessons en même temps.
Tous les hôtes sur lesquels vous installez ECE appartiennent à une zone de disponibilité, que vous pouvez spécifier lors de l’installation grâce au paramètre –availability-zone. Si vous ne spécifiez pas de zone de disponibilité, le script d’installation utilisera ece-zone-1 par défaut.
En général, vous devez suivre les directives ci-dessous pour choisir le nombre de zones de disponibilité dont vous avez besoin :
une seule zone de disponibilité convient pour les essais et le développement
deux zones de disponibilité sont adaptées à une utilisation en production avec un bris d’égalité
trois zones de disponibilité sont idéales pour les environnements critiques
Les bris d’égalité sont utilisés dans les grappes distribuées pour éviter les cas de division du cerveau, où les grappes se divisent en plusieurs parties autonomes qui continuent à traiter les demandes indépendamment les unes des autres, au risque d’affecter la cohérence de la grappe et la perte de données. Vous pouvez éviter un scénario de “split brain” en vous assurant qu’il doit y avoir une majorité de quorum de (n/2) + 1 nœuds, où n est le nombre de nœuds, pour qu’une partie quelconque de la grappe élise un nœud maître et accepte les demandes des utilisateurs. Cela signifie que pour une grappe de deux nœuds et une grappe de trois nœuds, vous devez avoir deux nœuds disponibles pour atteindre le quorum.
Si vous n’avez que deux zones de disponibilité, ECE désactive la création d’un cluster avec deux zones de disponibilité car il n’y a pas d’endroit fiable pour placer le tie-breaker, car il aurait une chance sur deux de faire partie de la zone de disponibilité survivante en cas de défaillance, ce qui ne suffit pas à garantir un quorum pour chaque défaillance possible.
Si vous avez trois zones de disponibilité, ECE peut placer le bris d’égalité dans la troisième zone de disponibilité lorsque vous créez un cluster avec des nœuds dans deux zones de disponibilité. Le fait de placer le bris d’égalité dans la troisième zone de disponibilité permet d’établir un quorum en cas de perte d’une zone de disponibilité et il n’est pas nécessaire que ce soit un nœud à part entière et coûteux, car il ne contient pas de données.
Pour définir dans une installation ECE une zone de haute disponbilité :
bash \
<(curl -fsSL https://download.elastic.co/cloud/elastic-cloud-enterprise.sh) \
install --cloud-enterprise-version 2.1.0 --availability-zone myzone
Topologie
La meilleure pratique consiste à disposer de nœuds maîtres dédiés dans des grappes plus importantes, de sorte que les nœuds maîtres n’aient pas besoin de s’occuper du travail de recherche ou d’indexation. Lorsque vous créez une grappe, vous pouvez spécifier l’utilisation de nœuds maîtres dédiés, un par zone de disponibilité.
Vous devez également éviter tout point de défaillance unique qui pourrait faire tomber l’ECE. Par exemple, si vous créez une installation qui utilise un seul rack physique avec plusieurs zones de disponibilité placées sur le même rack, ce rack devient un point de défaillance unique potentiel, car l’ensemble de votre cluster sera forcé de se déconnecter si le rack subit une panne ou une défaillance matérielle. Pour rendre votre installation plus tolérante aux pannes, vous devez créer des zones de disponibilité qui ne dépendent pas du même rack physique, et vous devez également prévoir une capacité suffisante pour maintenir votre charge de travail même si une zone de disponibilité tombe en panne.
Sépéaration des rôles
Lorsque vous installez ECE sur le premier hôte, on lui attribue différents rôles de coureur : allocator, coordinator, director, and proxy. Cette attribution de rôle est nécessaire pour faire connaître vos premiers développements. Dans un environnement de production, certains de ces rôles doivent être séparés, car leurs charges s’échelonnent différemment et peuvent créer des demandes conflictuelles lorsqu’elles sont placées sur le même hôte. La séparation des rôles permet également de répondre à certaines implications en matière de sécurité.
Voici les rôles que vous ne devez pas permettre à un même coureur de tenir :
les runners et les coordinateurs
les runners et les directeurs
coordinateurs et proxy
Si cette séparation des rôles n’est pas possible, vous pouvez utiliser moins d’hôtes qui fournissent des ressources matérielles importantes avec un stockage SSD rapide, bien qu’il soit recommandé de n’utiliser cette configuration que pour le développement, les tests et les cas d’utilisation à petite échelle.
Si vous ne pouvez pas utiliser le stockage SSD uniquement, vous devez séparer les services de gestion ECE fournis par les coordinateurs et les directeurs de vos mandataires et attributeurs et les placer sur des hôtes différents qui utilisent le stockage SSD rapide. Cela signifie que vous pouvez permettre en toute sécurité à un même coureur d’occuper à la fois les rôles de directeur et de coordinateur.
Exemple d’une petite installation :
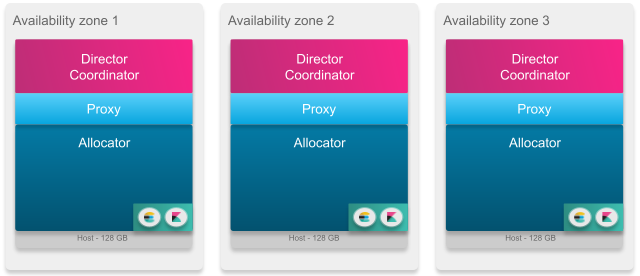
Exemple d’une moyenne installation :
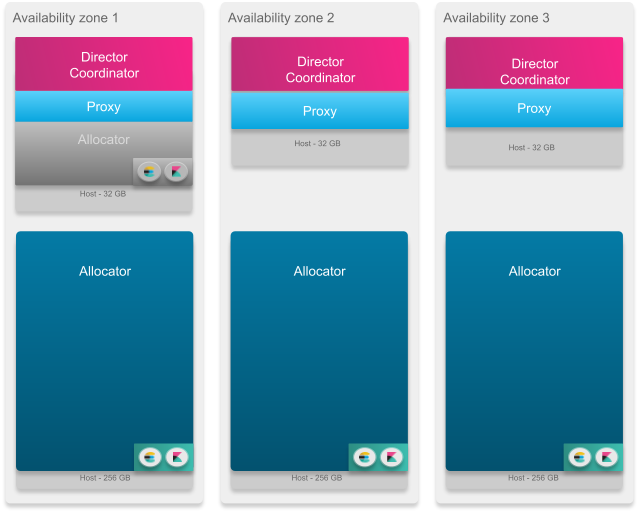
Exemple d’une grande installation :
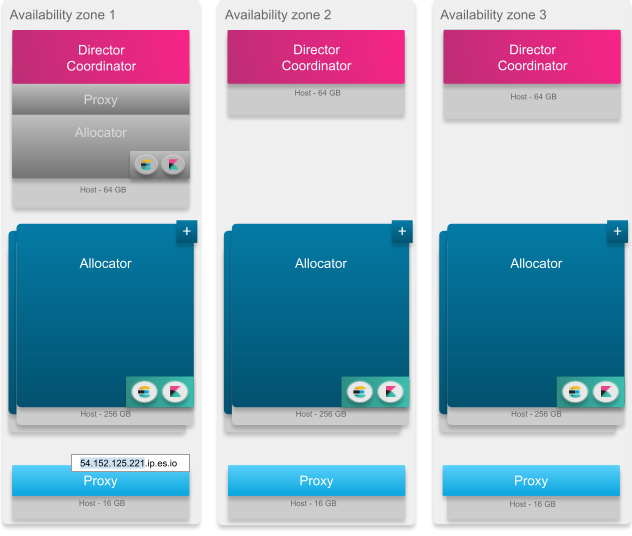
Augmenter les capacités
Elastic Cloud Enterprise s’adapte à toutes les capacités dont vous avez besoin.
Si vous avez besoin de plus de capacité de traitement parce que vos allocateurs sont sur le point d’être épuisés, installez ECE sur des hôtes supplémentaires et attribuez leur le rôle d’allocateur. Le constructeur reconnaît immédiatement ces ressources supplémentaires et les met à disposition afin qu’elles puissent commencer à traiter les demandes des utilisateurs.
Si vous constatez que l’unité centrale et la mémoire de vos serveurs proxy existants sont épuisées, vous devriez envisager d’ajouter un autre serveur proxy. N’oubliez pas que les proxy qui redirigent les demandes d’utilisateurs doivent s’adapter en fonction des demandes d’ingestion et de recherche sur vos instances Elasticsearch et Kibana. La charge des proxies dépend également de l’algorithme spécifié par votre équilibreur de charge.
Si la charge globale sur l’infrastructure de votre installation ECE commence à atteindre son maximum, vous devriez envisager d’ajouter d’autres coordinateurs et directeurs. Dans les environnements de production, il est recommandé de toujours utiliser au moins trois directeurs et coordinateurs, en séparant de préférence ces rôles. Cependant, même un déploiement à grande échelle ne devra probablement pas dépasser cinq directeurs et coordinateurs.
Questionnaire
- Sur quel concept repose la haute disponibilité ?
- Zones de fin
- NP-complétude
- Zones de disponbilité
- Zones de stockages
- La Haute Disponibilité requiert un minimum de ___ instances de la ECE.
- 1
- 2
- 3
- 4
- Chaque instance d’EPE est tenue d’exécuter chacun des rôles.
- Vrai
- Faux