Monitoring Prometheus et Grafana
Monitoring Prometheus et Grafana
Configurer le monitoring de etcd
Si le service etcd ne fonctionne pas correctement, le bon fonctionnement de l’ensemble du cluster OKD est en danger. Il est donc raisonnable de configurer la surveillance du service etcd.
Suivez les étapes suivantes pour configurer la surveillance d’etcd :
Vérifiez que la pile de surveillance est en marche :
oc -n openshift-monitoring get pods
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 3/3 Running 0 34m
alertmanager-main-1 3/3 Running 0 33m
alertmanager-main-2 3/3 Running 0 33m
cluster-monitoring-operator-67b8797d79-sphxj 1/1 Running 0 36m
grafana-c66997f-pxrf7 2/2 Running 0 37s
kube-state-metrics-7449d589bc-rt4mq 3/3 Running 0 33m
node-exporter-5tt4f 2/2 Running 0 33m
node-exporter-b2mrp 2/2 Running 0 33m
node-exporter-fd52p 2/2 Running 0 33m
node-exporter-hfqgv 2/2 Running 0 33m
prometheus-k8s-0 4/4 Running 1 35m
prometheus-k8s-1 0/4 ContainerCreating 0 21s
prometheus-operator-6c9fddd47f-9jfgk 1/1 Running 0 36m
Ouvrez le fichier de configuration de la pile de surveillance du cluster :
oc -n openshift-monitoring edit configmap cluster-monitoring-config
Sous config.yaml : |+, ajoutez la section etcd.
Si vous exécutez etcd dans des pods statiques sur vos nœuds maîtres, vous pouvez spécifier les nœuds etcd à l’aide du sélecteur :
...
data:
config.yaml: |+
...
etcd:
targets:
selector:
openshift.io/component: etcd
openshift.io/control-plane: "true"
Vérifiez que le moniteur du service etcd est en cours d’exécution :
oc -n openshift-monitoring get servicemonitor
NAME AGE
alertmanager 35m
etcd 1m
kube-apiserver 36m
kube-controllers 36m
kube-state-metrics 34m
kubelet 36m
node-exporter 34m
prometheus 36m
prometheus-operator 37m
Le moniteur du service etcd.
Il peut s’écouler jusqu’à une minute avant que le moniteur du service etcd ne démarre.
Vous pouvez maintenant accéder à l’interface web pour obtenir plus d’informations sur l’état de la surveillance du service etcd.
Pour obtenir l’URL, lancez :
oc -n openshift-monitoring get routes
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
...
prometheus-k8s prometheus-k8s-openshift-monitoring.apps.msvistun.origin-gce.dev.openshift.com prometheus-k8s web reencrypt None
En utilisant https, naviguez jusqu’à l’URL indiquée pour prometheus-k8s. Connectez-vous.
Assurez-vous que l’utilisateur appartient au rôle de surveillance du cluster. Ce rôle donne accès à la visualisation des interfaces utilisateur de surveillance des clusters.
Par exemple, pour ajouter l’utilisateur développeur au rôle de surveillance des clusters, lancez
oc adm policy add-cluster-role-to-user cluster-monitoring-view developer
Dans l’interface web, connectez-vous en tant qu’utilisateur appartenant au rôle de surveillance du cluster.
Cliquez sur Statut, puis sur Cibles. Si vous voyez une entrée etcd, etcd est surveillé.
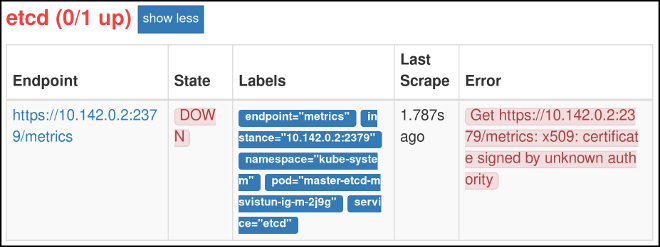
Bien que le système etcd soit désormais surveillé, Prométhée n’est pas encore en mesure de s’authentifier par rapport au système etcd et ne peut donc pas recueillir de données.
Pour configurer l’authentification de Prometheus par rapport à etcd
Copiez les fichiers d’identification /etc/etcd/ca/ca.crt et /etc/etcd/ca/ca.key du nœud maître vers la machine locale :
cp ca.* /opt/etcd-ssl/
Créez le fichier openssl.cnf avec ce contenu :
[ req ]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[ req_distinguished_name ]
[ v3_req ]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, keyEncipherment, digitalSignature
extendedKeyUsage=serverAuth, clientAuth
Générez le fichier de clé privée etcd.key :
openssl genrsa -out etcd.key 2048
Générer le fichier de demande de signature de certificat etcd.csr :
openssl req -new -key etcd.key -out etcd.csr -subj "/CN=etcd" -config openssl.cnf
Générer le fichier de certificat etcd.crt :
openssl x509 -req -in etcd.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out etcd.crt -days 365 -extensions v3_req -extfile openssl.cnf
Mettre les informations d’identification dans le format utilisé par OKD :
cat <<-EOF > etcd-cert-secret.yaml
apiVersion: v1
data:
etcd-client-ca.crt: "$(cat ca.crt | base64 --wrap=0)"
etcd-client.crt: "$(cat etcd.crt | base64 --wrap=0)"
etcd-client.key: "$(cat etcd.key | base64 --wrap=0)"
kind: Secret
metadata:
name: kube-etcd-client-certs
namespace: openshift-monitoring
type: Opaque
EOF
Ceci crée le fichier etcd-cert-secret.yaml
Appliquer le fichier de justificatifs d’identité au cluster :
oc apply -f etcd-cert-secret.yaml
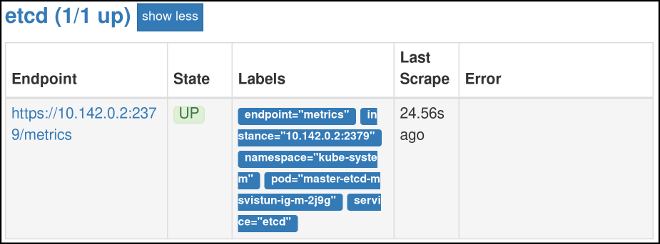
Maintenant que vous avez configuré l’authentification, visitez à nouveau la page Cibles de l’interface web. Vérifiez que etcd est maintenant correctement surveillé. Il peut s’écouler plusieurs minutes avant que les changements ne prennent effet.
Accès à Prometheus, Alertmanager et Grafana
OKD Monitoring est équipé d’une instance Prométhée pour la surveillance des clusters et d’un cluster central Alertmanager. En plus de Prometheus et d’Alertmanager, OKD Monitoring comprend également une instance Grafana ainsi que des tableaux de bord pré-construits pour le dépannage de la surveillance des clusters. L’instance Grafana qui est fournie avec la pile de surveillance, ainsi que ses tableaux de bord, est en lecture seule.
Pour obtenir les adresses d’accès aux interfaces web de Prometheus, Alertmanager et Grafana :
Exécutez la commande suivante :
oc -n openshift-monitoring get routes
NAME HOST/PORT
alertmanager-main alertmanager-main-openshift-monitoring.apps._url_.openshift.com
grafana grafana-openshift-monitoring.apps._url_.openshift.com
prometheus-k8s prometheus-k8s-openshift-monitoring.apps._url_.openshift.com
Veillez à faire précéder https:// de ces adresses. Vous ne pouvez pas accéder aux interfaces web en utilisant des connexions non cryptées.
L’authentification est effectuée par rapport à l’identité de l’OKD et utilise les mêmes informations d’identification ou moyens d’authentification que ceux utilisés ailleurs dans l’OKD. Vous devez utiliser un rôle qui a un accès en lecture à tous les espaces de noms, comme le rôle cluster-monitoring-view cluster.